Usage of sets and dense rank while developing Top N reports in Tableau
There is whole lot of information on ranks in Tableau. While developing Tableau reports with dynamic parameters like Top N, it’s very important to understand the order of operations in Tableau.
Below article from Tableau, order of operations was explained in more detail. Tableau’s Order of Operations.
I would like to share here one case, where sets can help along with dense rank for a Top N report. This is a very simple and sample case to understand the usage.
An organization “ABC”, which is very sustainability centric and focuses more in contributing to society using “Sustainability Development Goals (SDG)” as guidelines. Organization “ABC” has its branches all over the world, huge budgets were allocated to its “Corporate Social Responsibilities (CSR)” activities. CSR management team showed interest to get more insights about CSR activities and how budgets were flowing in contributing to different SDG’s.
This is very straight forward question to understand budgets spent, a spread sheet would be a direct answer. Let the questionnaire from management is in a multidimensional way, like below:
- What are Top N locations, which had spent a certain amount.
- What are Top N Sustainable Development Goals ’s our organization is contributing by number of employees participating.
- It’s obvious Top N w.r.t to Locations, Amount spent or contribution towards SDG’s is where more employees participating or more budget is spent. Management needs a deeper insight to consolidate all the rest of locations budget spent other than Top N(Location w.r.t SDG is TOP N, it shouldn’t contribute in rest of Locations category).
Lets dive into the solution to answer all 3 questions:
A quick look at sample data:

In Sample data, from location “Newport”, employees from this branch were contributing towards 2 SDG’s (SDG1 & SDG7). We will talk about this again during solving question3.
As a first step, create Top N according to amount spent or employees participated w.r.t location and SDG’s.
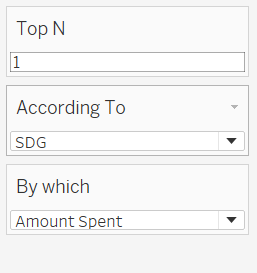
Create a “Top N” parameter , where user can pass value as parameter.
Create another parameter “According To” , where “Top N” value is passed to.

Create another parameter “By which” which is to visualize according to “Amount Spent” or “Number of employees participated”.
A detailed KB from Tableau, how to create TOP N by measure.
Using a Top N Parameter to Filter a Table | Tableau Software
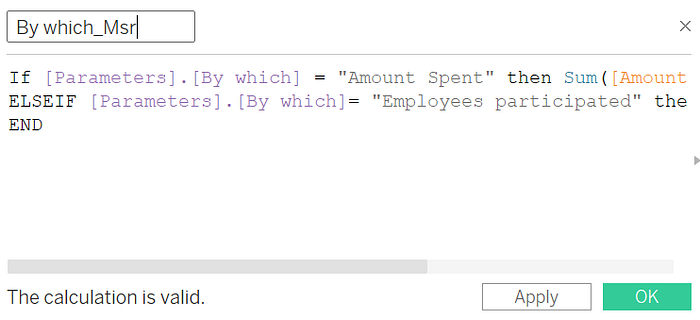
Now, create 2 calculated fields , using 2 parameters “According To” and “By which” to map arguments.

In the same way using “By which” parameter, create another calculated field to map measure values.
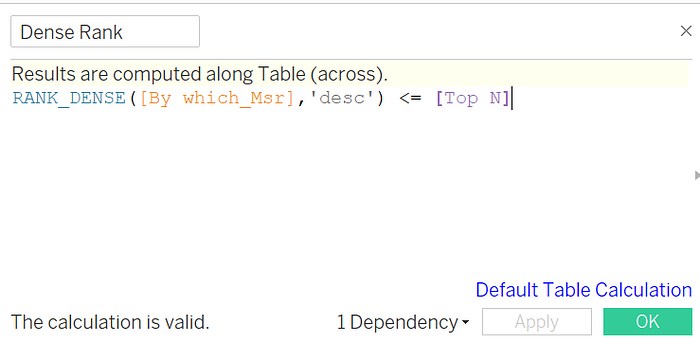
As we are ready by setting up all the parameters, lets start exploring on Dense Rank.
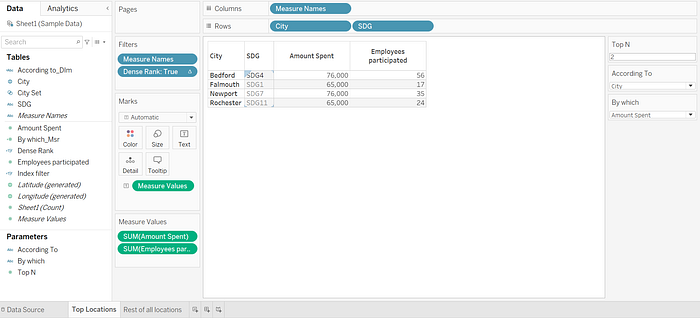
Creating a dense rank on “By which_Msr” parameter, as we have duplicate values for SDG like “Newport” city data we had seen in picture.1.
Below result for Top 2 Cities contributed to City by amount spent
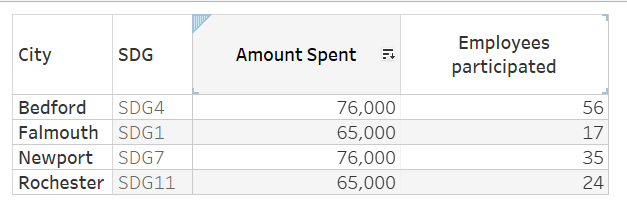
That answers our 1st and 2nd questions easily.
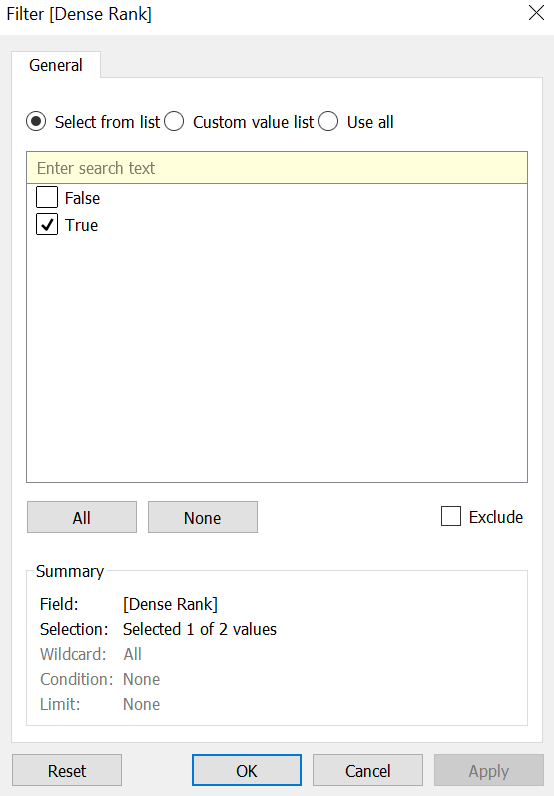
Now let’s look into 3rd question, first part of it. Consolidating all data that does not fall under Top N cities. Easy way to do this is take “Dense rank ” filter as false in another sheet and visualize. This is valid when we have unique data with no duplicates. The reason we are using dense rank here is to handle this duplicate data.
Suitable solution here is to use sets in our second sheet. Lets create a set on city.

Now, take City set to filters in rest of locations sheet and set it to “Out.” and then perform “Add column Grand Totals ”
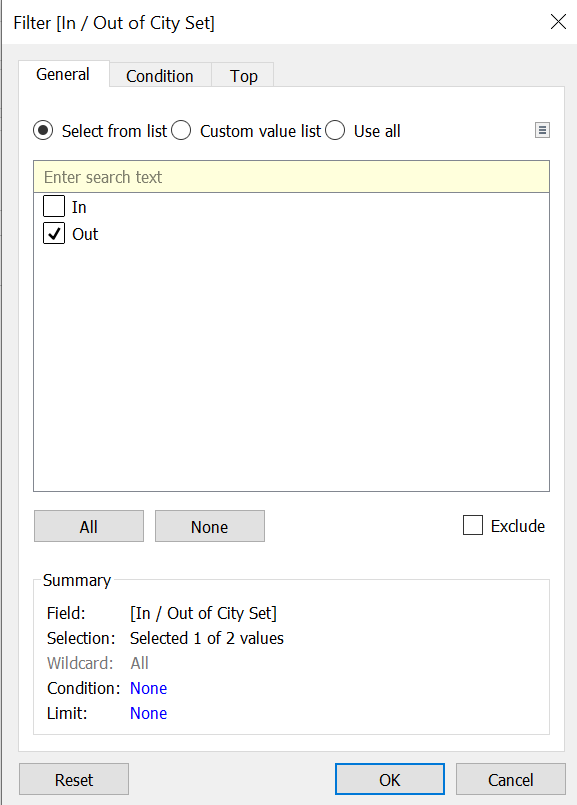
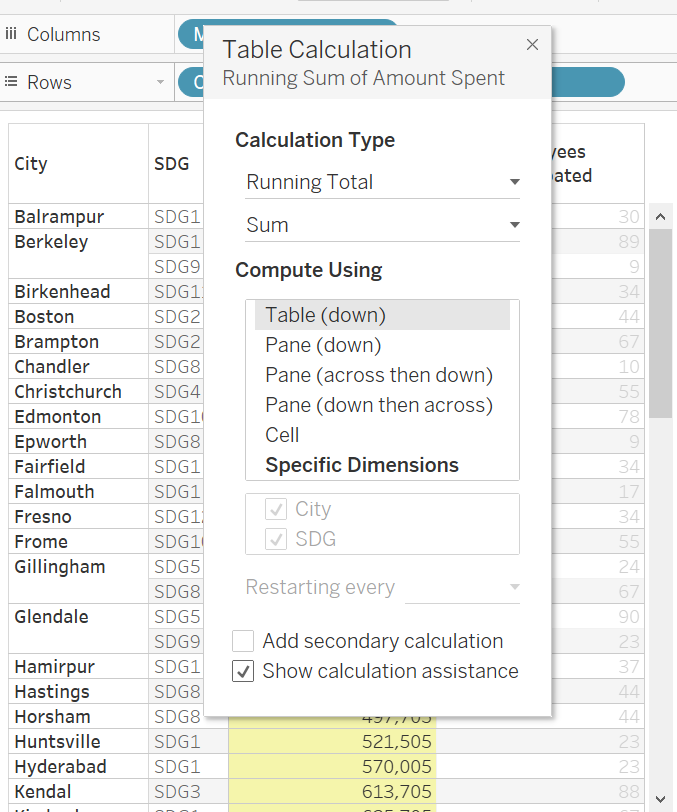
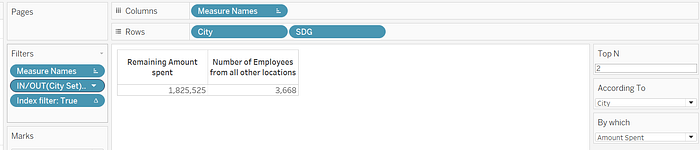
To answer our 3rd question , Newport data which contributes to both SDG’s, as it is in Top N, the second contribution is not added to rest of all locations data. Now perform a Running Total Table calculation on measure “Amount Spent”.
Since we need to display only Total amount spent in single row, lets use Index last() here to display last maximum value row after running total.
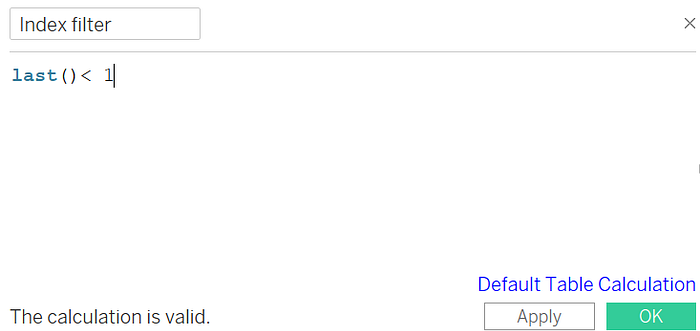
Drag this to filters and mark as “True”.
This gives a final output for Top n according to city and amount spent at least in 1 SDG, and remaining amount spent at different locations other than that present in Top N.
Rank functions are useful while handling Top N requirements, when cases like duplicate data dense rank functions are very helpful. Due to Dense rank, same ranks allocated , there might be an ambiguity during calculations. that is where Sets comes very handy to help solve these duplicate data issues.
Resource Links: